It’s not difficult to find free CompTIA Data+ DA0-001 exam questions now! You may already know that there are many free exam questions that can be found through search engines, but you also know that they are just outdated content and will not be of much help to your actual exam.

The truly practical and effective CompTIA Data+ DA0-001 exam questions must be protected. You can find the truly protected CompTIA Data+ DA0-001 exam questions and answers on Pass4itsure.
Before that, you can verify part of the Pass4itsure CompTIA Data+ DA0-001 exam questions and answers online, and they will be guaranteed to be valid in real-time when you actually get the complete material.
CompTIA Data+ DA0-001 exam questions online practice test
| From | Number of exam questions | Related |
| Pass4itsure | 15 (Free) | CompTIA A+ |
Question 1:
Which of the ing is the correct ion for a tab-delimited spre file?
A. tap
B. tar
C. sv
D. az
Correct Answer: C
Explanation:
A tab-delimited spreadsheet file is a type of flat text file that uses tabs as delimiters to separate data values in a table. The file extension for a tab-delimited spreadsheet file is usually .tsv, which stands for tab-separated values.
Therefore, the correct answer is C.
References: [Tab-separated values – Wikipedia], [What is a TSV File? | How to Open, Edit and Convert TSV Files]
Question 2:
Which of the following best describes the law of large numbers?
A. As a sample size decreases, its standard deviation gets closer to the average of the whole population.
B. As a sample size grows, its mean gets closer to the average of the whole population
C. As a sample size decreases, its mean gets closer to the average of the whole population.
D. When a sample size doubles. the sample is indicative of the whole population.
Correct Answer: B
The best answer is B.
As a sample size grows, its mean gets closer to the average of the whole population. The law of large numbers, in probability and statistics, states that as a sample size grows, its mean gets closer to the average of the whole population.
This is due to the sample being more representative of the population as it increases in size. The law of large numbers guarantees stable long-term results for the averages of some random events1 A.
As a sample size decreases, its standard deviation gets closer to the average of the whole population is not correct, because it confuses the concepts of standard deviation and mean. Standard deviation is a measure of how much the values in a data set vary from the mean, not how close the mean is to the population average.
Also, as a sample size decreases, its standard deviation tends to increase, not decrease, because the sample becomes less representative of the population.
C. As a sample size decreases, its mean gets closer to the average of the whole population is not correct, because it contradicts the law of large numbers. As a sample size decreases, its mean tends to deviate from the average of the whole population, because the sample becomes less representative of the population.
D. When a sample size doubles, the sample is indicative of the whole population is not correct, because it does not specify how close the sample mean is to the population average. Doubling the sample size does not necessarily make the sample indicative of the whole population, unless the sample size is large enough to begin with.
The law of large numbers does not state a specific number or proportion of samples that are indicative of the whole population, but rather describes how the sample mean approaches the population average as the sample size increases indefinitely.
Question 3:
A recurring event is being stored in two databases that are housed in different geographical locations. A data analyst notices the event is being logged three hours earlier in one database than in the other database. Which of the following is the MOST likely cause of the issue?
A. The data analyst is not querying the databases correctly.
B. The databases are recording different events.
C. The databases are recording the event in different time zones.
D. The second database is logging incorrectly.
Correct Answer: C
Explanation:
The most likely cause of the issue is that the databases are recording the event in different time zones. A time zone is a region that observes a uniform standard time for legal, commercial, and social purposes. Different time zones have different offsets from Coordinated Universal Time (UTC), which is the primary time standard by which the world regulates clocks and time.
For example, UTC-5 is five hours behind UTC, while UTC+3 is three hours ahead of UTC. If an event is being stored in two databases that are housed in different geographical locations with different time zones, it may appear that the event is being logged at different times, depending on how the databases handle the time zone conversion.
For example, if one database records the event in UTC-5 and another database records the event in UTC+3, then an event that occurs at 12:00 PM in UTC-5 will appear as 9:00 AM in UTC+3. The other options are not likely causes of the issue, as they are either unrelated or implausible.
The data analyst is not querying the databases incorrectly, as this would not affect the time stamps of the events.
The databases are not recording different events, as they are supposed to record the same recurring event. The second database is not logging incorrectly, as there is no evidence or reason to assume that.
Reference: [Time zone – Wikipedia]
Question 4:
Consider the following dataset which contains information about houses that are for sale:

Which of the following string manipulation commands will combine the address and region name columns to create a full address?
full_address————————- 85 Turner St, Northern Metropolitan 25 Bloomburg St, Northern Metropolitan 5 Charles St, Northern Metropolitan 40 Federation La, Northern Metropolitan 55a Park St, Northern Metropolitan
A. SELECT CONCAT(address, \’ , \’ , regionname) AS full_address FROM melb LIMIT 5;
B. SELECT CONCAT(address, \’-\’ , regionname) AS full_address FROM melb LIMIT 5;
C. SELECT CONCAT(regionname, \’ , \’ , address) AS full_address FROM melb LIMIT 5
D. SELECT CONCAT(regionname, \’-\’ , address) AS full_address FROM melb LIMIT 5;
Correct Answer: A
The correct answer is A:
SELECT CONCAT(address, \’ , \’ , regionname) AS full_address FROM melb LIMIT 5;
String manipulation (or string handling) is the process of changing, parsing, splicing, pasting, or analyzing strings. SQL is used for managing data in a relational database.
The CONCAT () function adds two or more strings together. Syntax CONCAT(stringl, string2,… string_n) Parameter Values Parameter Description stringl, string2, string_n Required. The strings to add together.
Question 5:
While reviewing survey data, an analyst notices respondents entered “Jan,” “January,” and “01” as responses for the month of January. Which of the following steps should be taken to ensure data consistency?
A. Delete any of the responses that do not have “January” written out.
B. Replace any of the responses that have “01”.
C. Filter on any of the responses that do not say “January” and update them to “January”.
D. Sort any of the responses that say “Jan” and update them to “01”.
Correct Answer: C
Explanation: Filter on any of the responses that do not say “January” and update them to “January”. This is because filtering and updating are data cleansing techniques that can be used to ensure data consistency, which means that the data is uniform and follows a standard format.
By filtering on any of the responses that do not say “January” and updating them to “January”, the analyst can make sure that all the responses for the month of January are written in the same way. The other steps are not appropriate for ensuring data consistency.
Here is why:
Deleting any of the responses that do not have “January” written out would result in data loss, which means that some information would be missing from the data set. This could affect the accuracy and reliability of the analysis.
Replacing any of the responses that have “01” would not solve the problem of data inconsistency, because there would still be two different ways of writing the month of January: “Jan” and “January”. This could cause confusion and errors in the analysis.
Sorting any of the responses that say “Jan” and updating them to “01” would also not solve the problem of data inconsistency, because there would still be two different ways of writing the month of January: “01” and “January”. This could also cause confusion and errors in the analysis.
Question 6:
Jhon is working on an ELT process that sources data from six different source systems.
Looking at the source data, he finds that data about the sample people exists in two of six systems.
What does he have to make sure he checks for in his ELT process?
Choose the best answer.
A. Duplicate Data.
B. Redundant Data.
C. Invalid Data.
D. Missing Data.
Correct Answer: C
Duplicate Data.
While invalid, redundant, or missing data are all valid concerns, data about people exists in two of the six systems. As such, Jhon needs to account for duplicate data issues.
Question 7:
Given the following customer and order tables:
Which of the following describes the number of rows and columns of data that would be present after performing an INNER JOIN of the tables?
A. Five rows, eight columns
B. Seven rows, eight columns
C. Eight rows, seven columns
D. Nine rows, five columns
Correct Answer: B
Explanation: This is because an INNER JOIN is a type of join that combines two tables based on a matching condition and returns only the rows that satisfy the condition. An INNER JOIN can be used to merge data from different tables that have a common column or a key, such as customer ID or order ID. To perform an INNER JOIN of the customer and order tables, we can use the following SQL statement:

This statement will select all the columns (*) from both tables and join them on the customer ID column, which is the common column between them. The result of this statement will be a new table that has seven rows and eight columns, as shown below:
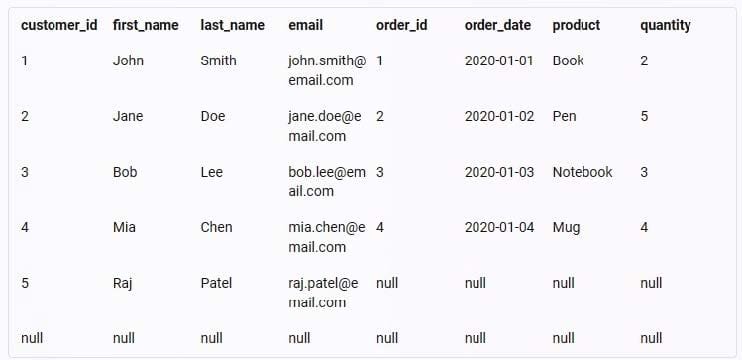
The reason why there are seven rows and eight columns in the result table is because:
There are seven rows because there are six customers and six orders in the original tables, but only five customers have matching orders based on the customer ID column.
Therefore, only five rows will have data from both tables, while one row will have data only from the customer table (customer 5), and one row will have no data at all (null values).
There are eight columns because there are four columns in each of the original tables, and all of them are selected and joined in the result table.
Therefore, the result table will have four columns from the customer table (customer ID, first name, last name, and email) and four columns from the order table (order ID, order date, product, and quantity).
Question 8:
Different people manually type a series of handwritten surveys into an online database. Which of the following issues will MOST likely arise with this data? (Choose two.)
A. Data accuracy
B. Data constraints
C. Data attribute limitations
D. Data bias
E. Data consistency
F. Data manipulation
Correct Answer: AE
Data accuracy refers to the extent to which the data is correct, reliable, and free of errors. When different people manually type a series of handwritten surveys into an online database, there is a high chance of human error, such as typos, misinterpretations, omissions, or duplications.
These errors can affect the quality and validity of the data and lead to incorrect or misleading analysis and decisions.
Data consistency refers to the extent to which the data is uniform and compatible across different sources, formats, and systems.
When different people manually type a series of handwritten surveys into an online database, there is a high chance of inconsistency, such as different spellings, abbreviations, formats, or standards. These inconsistencies can affect the integration and comparison of the data and lead to confusion or conflicts.
Therefore, to ensure data quality, it is important to have clear and consistent rules and procedures for data entry, validation, and verification. It is also advisable to use automated tools or methods to reduce human error and inconsistency.
Question 9:
A sales analyst needs to report how the sales team is performing to target. Which of the following files will be important in determining 2019 performance attainment?
A. 2018 goal data
B. 2018 actual revenue
C. 2019 goal data
D. 2019 commission plan
Correct Answer: C
Answer:
C. 2019 goal data To report how the sales team is performing to target, the sales analyst needs to compare the actual sales revenue with the expected or planned sales revenue for the same period. The 2019 goal data is the file that contains the expected or planned sales revenue for the year 2019, which is the target that the sales team is aiming to achieve. By comparing the 2019 goal data with the 2019 actual revenue, the sales analyst can calculate the performance attainment, which is the percentage of the goal that was met by the sales team.
Option A is incorrect, as 2018 goal data is not relevant for determining 2019 performance attainment. The 2018 goal data contains the expected or planned sales revenue for the year 2018, which is not the target that the sales team is aiming to achieve in 2019.
Option B is incorrect, as 2018 actual revenue is not relevant for determining 2019 performance attainment. The 2018 actual revenue contains the actual sales revenue for the year 2018, which is not comparable with the 2019 goal data or the 2019 actual revenue.
Option D is incorrect, as 2019 commission plan is not relevant for determining 2019 performance attainment. The 2019 commission plan contains the rules and rates for calculating and paying commissions to the sales team based on their performance attainment, but it does not contain the expected or planned sales revenue for the year 2019.
Question 10:
An analyst needs to join two tables of data together for analysis. All the names and cities in the first table should be joined with the corresponding ages in the second table, if applicable.
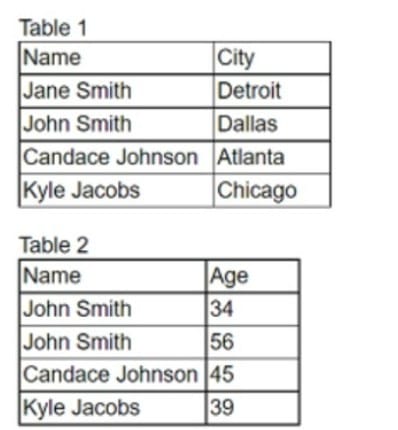
Which of the following is the correct join the analyst should complete. and how many total rows will be in one table?
A. INNER JOIN, two rows
B. LEFT JOIN. four rows
C. RIGHT JOIN. five rows
D. OUTER JOIN, seven rows
Correct Answer: B
Explanation:
The correct join the analyst should complete is B. LEFT JOIN, four rows. A LEFT JOIN is a type of SQL join that returns all the rows from the left table, and the matched rows from the right table. If there is no match, the right table will have null values. A LEFT JOIN is useful when we want to preserve the data from the left table, even if there is no corresponding data in the right table1 Using the example tables, a LEFT JOIN query would look like this:
SELECT t1.Name, t1.City, t2.Age FROM Table1 t1 LEFT JOIN Table2 t2 ON t1.Name = t2.Name;
The result of this query would be:
Name City Age Jane Smith Detroit NULL John Smith Dallas 34 Candace Johnson Atlanta 45 Kyle Jacobs Chicago 39
As you can see, the query returns four rows, one for each name in Table1. The name John Smith appears twice in Table2, but only one of them is matched with the name in Table1. The name Jane Smith does not appear in Table2, so the age column has a null value for that row.
Question 11:
Which of the following are reasons to create and maintain a data dictionary? (Choose two.)
A. To improve data acquisition
B. To remember specifics about data fields
C. To specify user groups for databases
D. To provide continuity through personnel turnover
E. To confine breaches of PHI data
F. To reduce processing power requirements
Correct Answer: BD
A data dictionary is a collection of metadata that describes the data elements in a database or dataset. It can help improve data acquisition by providing information about the data sources, formats, quality, and usage. It can also help remember specifics about data fields, such as their names, definitions, types, sizes, and relationships.
Therefore, options B and D are correct.
Option A is incorrect because it is not a reason to create and maintain a data dictionary, but a benefit of doing so.
Option C is incorrect because specifying user groups for databases is not a function of a data dictionary, but a function of a database management system or a security policy.
Option E is incorrect because confining breaches of PHI data is not a function of a data dictionary, but a function of a data protection or encryption system.
Option F is incorrect because reducing processing power requirements is not a function of a data dictionary, but a function of a data compression or optimization system.
Question 12:
Given the following:

Which of the following is the most important thing for an analyst to do when transforming the table for a trend analysis?
A. Fill in the missing cost where it is null.
B. Separate the table into two tables and create a primary key
C. Replace the extended cost field with a calculated field.
D. Correct the dates so they have the same format.
Correct Answer: D
Correcting the dates so they have the same format is the most important thing for an analyst to do when transforming the table for a trend analysis. Trend analysis is a method of analyzing data over time to identify patterns, changes, or relationships. To perform a trend analysis, the data needs to have a consistent and comparable format, especially for the date or time variables.
In the example, the date purchased column has two different formats: YYYY-MM-DD and MM/DD/YYYY. This could cause errors or confusion when sorting, filtering, or plotting the data over time.
Therefore, the analyst should correct the dates so they have the same format, such as YYYY-MM-DD, which is a standard and unambiguous format.
Question 13:
Which of the following are reasons to conduct data cleansing? (Select two).
A. To perform web scraping
B. To track KPls
C. To improve accuracy
D. To review data sets
E. To increase the sample size
F. To calculate trends
Correct Answer: CF
Two reasons to conduct data cleansing are:
To improve accuracy:
Data cleansing helps to ensure that the data is correct, consistent, and reliable. This can improve the quality and validity of the analysis, as well as the decision-making and outcomes based on the data12 To calculate trends:
Data cleansing helps to remove or resolve any errors, outliers, or missing values that could distort or skew the data. This can help to identify and measure the patterns, changes, or relationships in the data over time13
Question 14:
Joseph is interpreting a left skewed distribution of test scores. Joe scored at the mean, Alfonso scored at the median, and gaby scored and the end of the tail.
Who had the highest score?
A. Joseph
B. Joe
C. Alfonso
D. Gaby
Correct Answer: C
Alfonso had the highest score. A left skewed distribution is a distribution where the tail is longer on the left side than on the right side, meaning that most of the values are clustered on the right side and there are some outliers on the left side.
In a left skewed distribution, the mean is less than the median, which is less than the mode.
Therefore, Joseph, who scored at the mean, had the lowest score, Gaby, who scored at the end of the tail, had the second lowest score, and Alfonso, who scored at the median, had the highest score.
Reference: Skewness – Statistics How To
Question 15:
Kelly wants to get feedback on the final draft of a strategic report that has taken her six months to develop.
What can she do to get prevent confusion as see seeks feedback before publishing the report?
Choose the best answer.
A. Distribute the report to the appropriate stakeholders via email.
B. Use a watermark to identify the report as a draft.
C. Show the report to her immediate supervisor.
D. Publish the report on an internally facing website.
Correct Answer: B
The best answer is to use a watermark to identify the report as a draft. A watermark is a faint image or text that appears behind the content of a document, indicating its status or ownership. By using a watermark, Kelly can clearly communicate that the report is not final and still subject to changes or feedback.
This can prevent confusion among the readers and avoid any misuse or misinterpretation of the report. The other options are not as effective as using a watermark, as they either do not indicate the status of the report or do not reach the appropriate stakeholders.
Distributing the report via email or publishing it on an internally facing website may not make it clear that the report is a draft and may cause confusion or errors. Showing the report to her immediate supervisor may not get enough feedback from other relevant stakeholders who may have different perspectives or insights.
Reference: How to Add a Watermark in Microsoft Word – Lifewire
…
The last thing I want to say is that it is important where to get the latest CompTIA Data+ DA0-001 exam questions and answers! You must remember that the truly protected materials are the actual and effective exam materials, because they have paid a lot of money and put in a lot of effort to ensure that you pass the exam 100%. Download the latest 215 CompTIA Data+ DA0-001 exam questions and answers: https://www.pass4itsure.com/da0-001.html to ensure you pass successfully on the first try.